Let me introduce some of yall to the inverted yield curve and my predictions for the US economy.
The yield curve is just a graph answering the question "If the government wants to borrow money for a short time or long time, what are the interest rates loaners will agree to?"
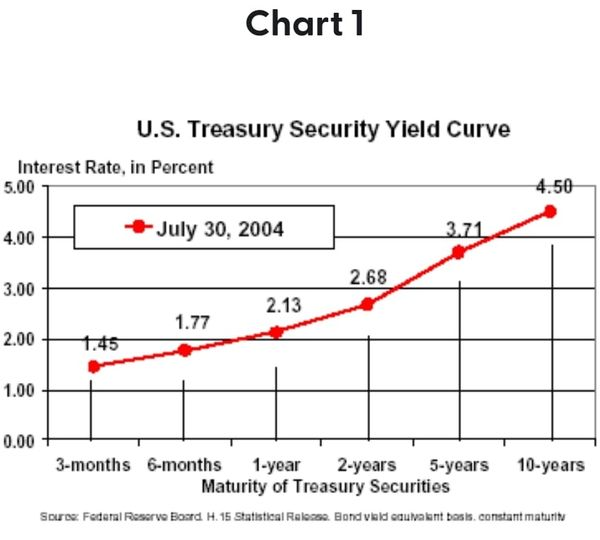
Normally, the graph looks like this. Loaners have a good idea what's gonna happen this year, so on the left, it's a relatively lower interest rate (a one year loan). But loaners don't know what will happen in 30 years, so they want a higher interest rate if they're gonna have their money tied up the whole time. Usually longer loans = riskier for the loaner, because they could have done lots of other stuff with that money.
Now, over the past 40 years, interest rates keep getting brought lower by the federal reserve. You can see that every time there's a financial crisis or recession, the fed lowers interest rates and gives everyone more money. You might ask "well, why doesn't the economy recover and then interest rates return to normal?"
The answer is the American people don't want reality, they want free stuff. From hedge fund managers to retirees to welfare queens, everyone wants more money for less work. And lowering interest rates is one way to do that.
So every time interest rates go lower, when the federal reserve tries to move them back to normal levels, people freak out, the stock market crashes, a recession happens, people get laid off, and politicians yell at the fed, who lower interest rates again.
You can see that we are running out of room to keep playing this game.
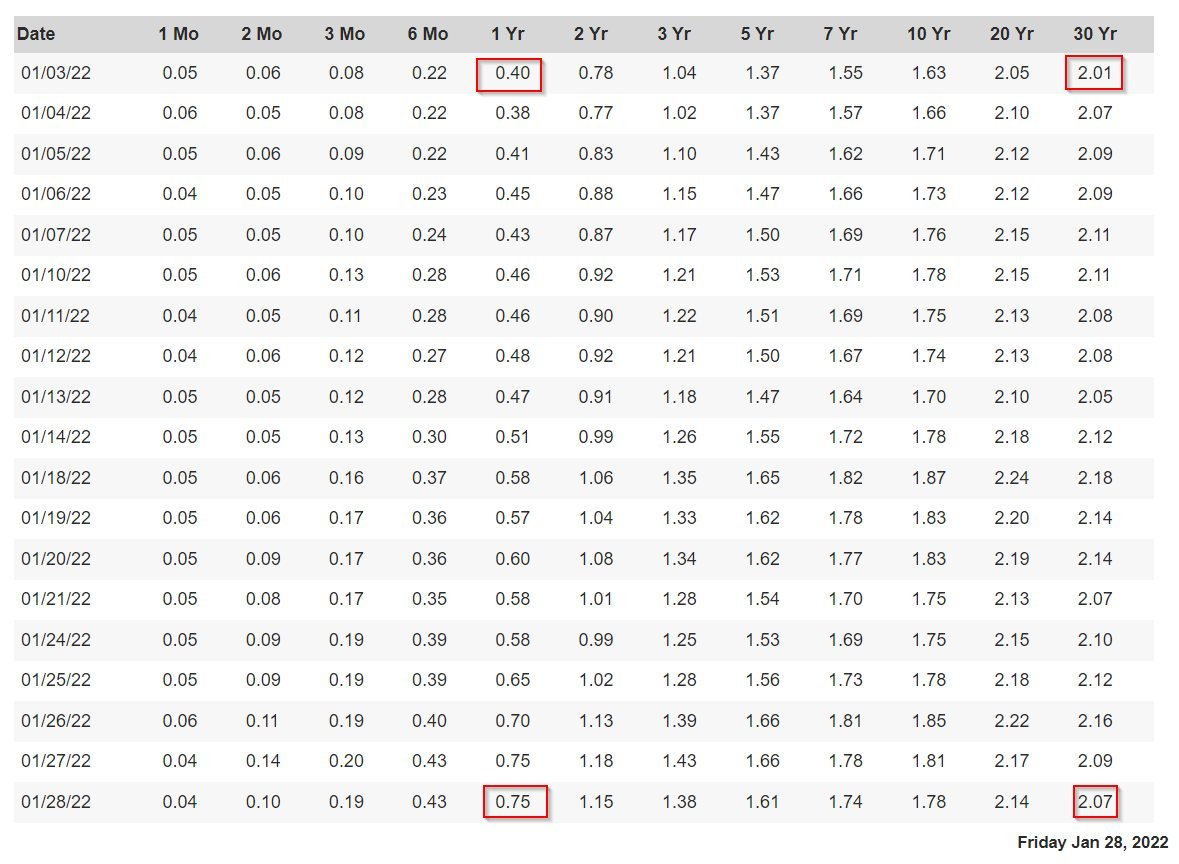
The inverted yield curve is what usually happens right before a recession. Remember, on the left is "How high is the interest rate when the government wants to borrow money for a year" and on the right is "How high is the interest rate when the government wants to borrow for 3 years."
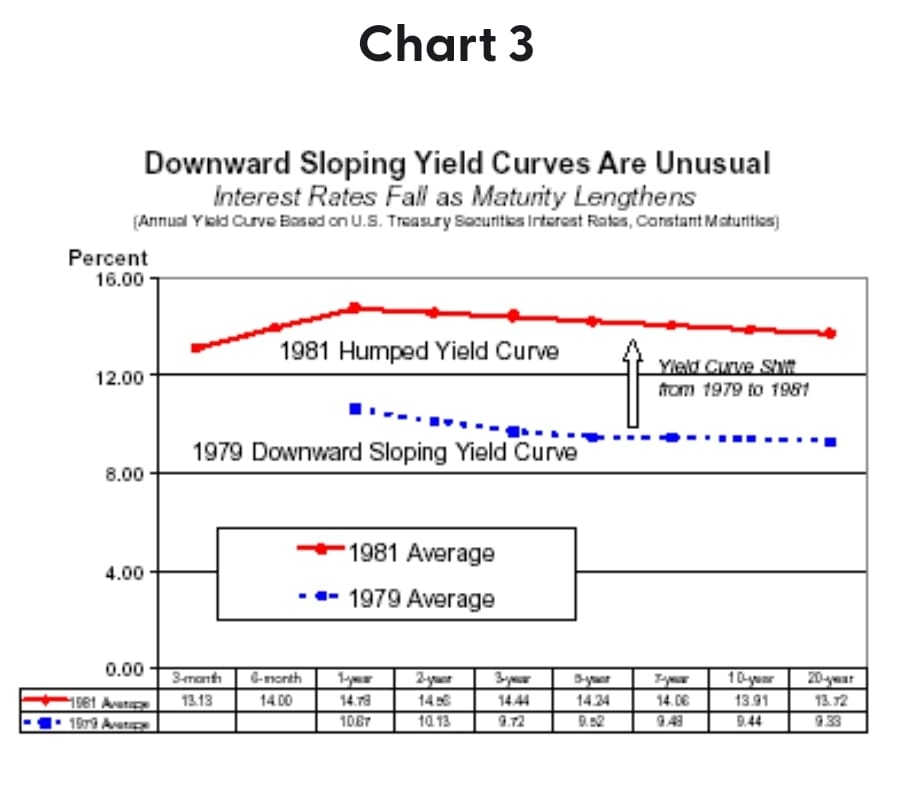
When people think there is a recession coming, they think the federal reserve will have to reduce interest rates. So they figure "Interest on long term loans should be lower, because rates are going to go down." It's called inverted because the left side is higher than the right side, which is the opposite of normal (see 1st graph).

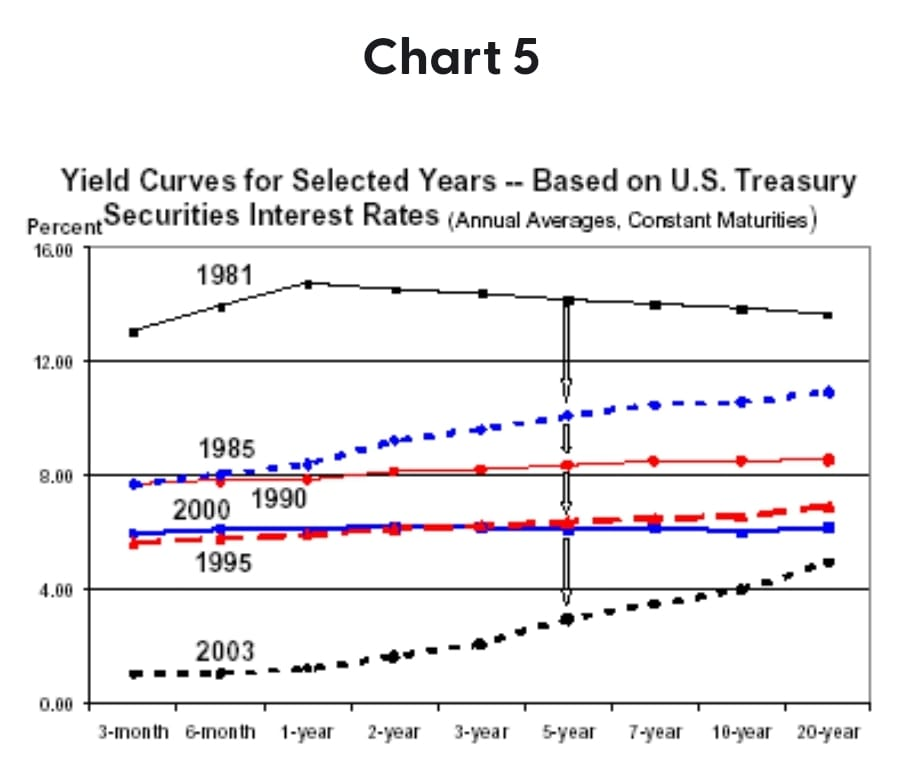
It's been true for a while that all of our economic growth was imaginary and just a result of free money from the fed. Tons of people are unemployed (see chart) but asset prices were skyrocketing. It's all fake. And we could keep it going until something (inflation) forced the federal reserve to turn off QE and raise rates. And here we are.
So the fed is turning off the printers and raising rates. This crashes the stock market and causes a recession. It won't be enough to immediately stop inflation from increasing.
It's possible that the fed will be able to raise rates slowly enough, and sell assets slowly enough, that they are able to deflate the bubble and reduce inflation without causing a full blown freakout recession. But I don't think that'll happen, for a few reasons:
1) Every time there's a recession, the rate ceiling for how high interest rates can go before the market freaks out gets lower. Right now, folks think it's like 2%, and we can't get 10% inflation under control without rates far higher than that.
2) The federal debt is fucking huge (see chart), and it gets worse every day. As interest rates go up, the federal debt goes up (obviously nobody wants to raise taxes in a recession), so there's a limit to how high interest rates can go. Basically, in a democracy, inflation is harder to blame on the government than tax hikes or spending cuts. So we will get a basket of the worst of all worlds - high inflation, cut spending, higher interest rates, probably higher taxes etc.
3) If we don't cut spending and raise taxes, it sends us further down the road toward an economic crisis like we've never seen, caused by the world losing faith in the US dollar as our debt to GDP ratio heads towards 3:1. A that point the government's interest rates skyrocket, the fed loses control, and hyperinflation is the only way to pay off the government debt and stabilize the situation.

Some of my recommendations for this year:
1) Some amazing tech stocks are down 50% already. Maybe scoop them up and hold for the long haul.
2) Stay as liquid as you can, but don't hold any cash at all. If you want something safe, VTIPS or STIP are inflation protected and are a good bet.
3) In a recession, utilities and insurance perform well. Everyone keeps paying. However, I'm unsure if utilities will be able to raise rates to keep up with inflation.
4) Do not panic sell. Just hang on through the ride.
5) Commodities tend to do well, because they can easily raise prices to keep up with inflation. But I don't know much about this space.
6) Cut your spending NOW and prepare. Turn off/pause all those monthly subscriptions, stop eating out, save your money. There are layoffs and brutal interest rates in the future.
7) Get the hell out of cryptocurrencies. They are not a hedge against inflation, they're a place that excess money goes. And pretty soon, there won't be any excess money.
8)This is the time to buy a house, before interest rates skyrocket. But there's reason to think house values will decline over the next few years. So you're gonna overpay and might be underwater at first.
9) Get out of small cap stocks. They get crushed during modern recessions because people sell mutual funds and there just aren't enough buyers.
All of this assumes the fed doesn't freak out and cut rates/resume QE. Which I just don't think they can do. But short term thinking has been the name of the game for so long, perhaps they'll find a way to forestall the inevitable again.





