Here's a quick walkthrough on how to download music from bandcamp.com into your android phone. First, you'll need to download an unzip app - Easy Unrar is free. Find it in the app store (Google Play) and download it.
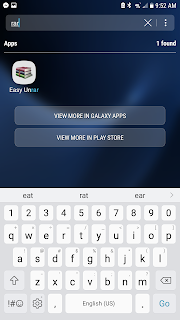 I'll throw red dots on these screenshots to make it easy for you to follow along.
I'll throw red dots on these screenshots to make it easy for you to follow along.
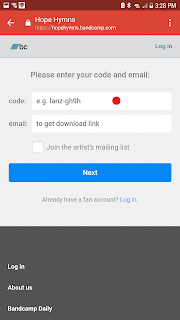
Next, get your download code and click on the link - for example, https://hopehymns.bandcamp

Now click "here's how"

Click the second "Here's how", then select your file type (I used MP3 220, but I'm not a music expert so YMMV). Then click download.

Great! Your music is downloaded. Now we need to unzip it. Open Easy Unrar and click the "Download" folder.

If you've had your phone awhile, it might be tough to wade through all the downloads and find your album. So click on the sort button on the upper right.

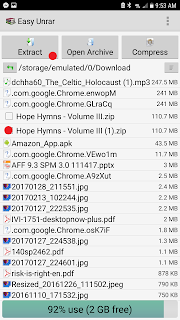
Choose sort by file size, large to small.
Since your album is probably more than 100MB, it should be near the top. Here you can see Hope Hymns, the album i want. Check the box and click Extract.

Check this box and click extract as well.

OK - good news and bad news. Bad news is you're not done, good news is you're almost done. Now we need Google Music to rescan and discover your unzipped album files. Open up the Settings app and click on Applications.

Now find and click Google Play Music


Almost done! Click Storage
!Important! DO NOT click "Clear Data." DO click "Clear Cache"
Now reboot your phone, open up Google Play Music, and you're done! Enjoy.
 I'll throw red dots on these screenshots to make it easy for you to follow along.
I'll throw red dots on these screenshots to make it easy for you to follow along.
Next, get your download code and click on the link - for example, https://hopehymns.bandcamp

Now click "here's how"

Click the second "Here's how", then select your file type (I used MP3 220, but I'm not a music expert so YMMV). Then click download.

Great! Your music is downloaded. Now we need to unzip it. Open Easy Unrar and click the "Download" folder.

If you've had your phone awhile, it might be tough to wade through all the downloads and find your album. So click on the sort button on the upper right.


Choose sort by file size, large to small.
Since your album is probably more than 100MB, it should be near the top. Here you can see Hope Hymns, the album i want. Check the box and click Extract.

Check this box and click extract as well.

OK - good news and bad news. Bad news is you're not done, good news is you're almost done. Now we need Google Music to rescan and discover your unzipped album files. Open up the Settings app and click on Applications.

Now find and click Google Play Music


Almost done! Click Storage

!Important! DO NOT click "Clear Data." DO click "Clear Cache"
Now reboot your phone, open up Google Play Music, and you're done! Enjoy.



















